What happens when engineers learn their craft from tech Twitter instead of actual experience. And why the most important blog post nobody writes is “I Fixed a Connection Leak.”
resume driven development
— IT Unprofessional (@it_unprofession) February 12, 2025
Somewhere out there, a developer is adding a message queue to a system that handles forty requests per day. Another one is refactoring a perfectly functional monolith into microservices because a conference talk made them feel bad about it. A third is seriously asking whether their three-person startup needs a service mesh.
All three learned engineering from the internet. All three are building the wrong thing for the wrong reasons. All three will write a Medium post about it that teaches someone else to do the same.
This is the cycle. Welcome to it.
The 80% Number That Proves Everything and Nothing
Let us start with facts, because this article deserves them.
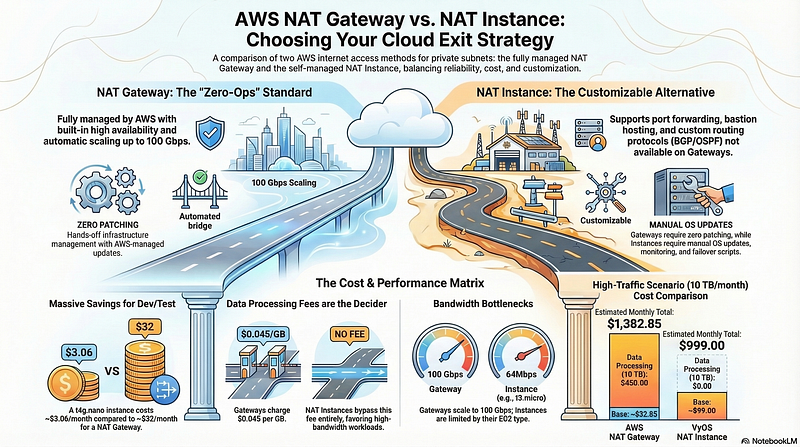
The Cloud Native Computing Foundation’s 2024 Annual Survey reported that 80% of organisations have Kubernetes running in production, up from 66% in 2023. The headline writes itself: “Kubernetes is the industry standard.” Tech Twitter celebrated accordingly.
Here is what the headline left out. The CNCF survey is answered by cloud-native practitioners. People who attend KubeCon. People for whom filling out a survey about container orchestration is a perfectly normal Tuesday. The sample is, by design, the exact population most likely to use Kubernetes. Asking that group whether they use Kubernetes is roughly equivalent to polling attendees at a car show about whether they own a car, then reporting that car ownership is universal.
Now look at the company-size breakdown from the same data. 91% of Kubernetes users work at companies with more than 1,000 employees. Only 9% come from companies with 500 to 1,000 employees. Below 500 employees, the numbers stop being reported because the sample gets too small to matter.
So the actual picture is this: Kubernetes is genuinely widespread among large enterprises with complex infrastructure requirements, hundreds of services and dedicated platform engineering teams. For everyone else, the survey is essentially not about them, even though the headline implies it is.
The 40-person company with twelve services running on AWS is not a Kubernetes anomaly. It is the statistical norm, quietly doing its job while the internet argues about Helm chart best practices.
Tech Twitter Is Not Your Infrastructure
There is a specific kind of distortion that happens when engineers learn primarily from social media and tech blogs. Call it the Survivorship Blog Problem.
The companies that write engineering blog posts are not representative companies. They are companies with engineering blogs. That sounds circular because it is. Netflix writes about how they handle streaming for 280 million subscribers. Uber writes about their geospatial indexing challenges. Google writes about everything Google does, at a scale that has no practical relevance to 99.9% of the industry.
These posts are interesting. They are worth reading. They are not a template.
The problem is not that these posts exist. The problem is that they are the visible content, so they become the reference point. A developer reads “How We Migrated to Kubernetes and Improved Reliability by 40%” and walks away thinking that Kubernetes is what you do when you want reliability. They do not read the companion post, which does not exist, titled “How We Spent Eight Months and $800,000 on a Migration That a Load Balancer Would Have Fixed.”
The second post would be more useful. Nobody writes it. It does not get shared. It does not look good in a job application portfolio.
This is the core distortion. The internet has a massive survivorship bias toward complexity, novelty and scale. Simple solutions that work perfectly are invisible. Boring fixes that save production at 2am are not tweeted about. The engineer who spent a Tuesday tracking down a database connection leak added four lines of code to fix it. They do not get a conference talk. The engineer who migrated the same database to a distributed architecture across three availability zones absolutely does.
Resume-Driven Development: The Industry’s Open Secret
There is a term for this in software engineering circles: Resume-Driven Development. It describes the practice of choosing technologies based on what looks impressive on a CV rather than what solves the actual problem. It is embarrassingly common. It is almost never discussed honestly in public because everyone doing it has an incentive to call it something else.
The pattern looks like this: a developer sees that Kubernetes experience commands a salary premium of $20,000 to $40,000 per year in the current market. LinkedIn confirms this. 110,000 Kubernetes-related job listings existed as of 2025, according to CNCF’s own data. The technology is in demand. Demand means negotiating power.
So when the opportunity arises to introduce Kubernetes at the current company, even a company where it solves no real problem, the calculus is not purely technical. The engineer gets Kubernetes experience. The company gets Kubernetes complexity. The engineer gets a raise at their next job. The company gets a three-page runbook for a system that used to require none.
This is not a moral failing. It is a rational response to misaligned incentives. The engineer’s career is optimised by learning what the job market values. The company’s product is optimised by solving the actual problem in the simplest reliable way. These goals are sometimes aligned. Sometimes they are in direct opposition. No amount of idealism changes the underlying incentive structure.
The honest version of this conversation would be entirely fine: “I want to learn Kubernetes and I’m looking for a project where it makes sense.” Everyone would understand it. Instead, the conversation is usually framed as a technical recommendation. That is where the problem starts.
The Blog Post Nobody Writes
Let us be specific about what actually matters in most production systems.
The connection leak. A query that opens a database connection without closing it properly is one of the most common and most damaging issues in production applications. It is not glamorous. It is not a distributed systems problem. It is four lines of missing cleanup code. The fix is a try-finally block or a context manager, depending on the language. The impact of fixing it is a database that stops falling over at peak load.
Nobody writes “I Fixed a Database Connection Leak” and gets 50,000 impressions on LinkedIn. But the developer who fixed that leak saved more actual business value than most Kubernetes migrations.
The N+1 query. An ORM that silently generates a separate database query for each item in a result set of 10,000 items is a page load that takes twelve seconds instead of 200 milliseconds. The fix is a join. The impact is a product that users do not abandon in frustration. It requires no new infrastructure. It requires understanding how your database actually works.
The uncached computation. A function that recalculates the same result on every request when the result changes once per hour is a CPU cost that scales linearly with traffic. Adding a cache with a sensible TTL is not exciting. It works.
None of these problems require Kubernetes. They do not require microservices. They do not require a distributed tracing system, a service mesh or a message queue. They require someone who understands the system well enough to find the real bottleneck, which is almost never where the interesting technology is.
The reason these fixes are not celebrated is precisely that they are unsexy. There is no conference talk about “I Added a Cache.” There is no hiring premium for “Experienced Connection Leak Detector.” So they remain invisible in the discourse, while architecture diagrams with sixteen boxes get liked and reshared.
What “Industry Standard” Actually Means
The phrase “industry standard” is the most abused term in technical decision-making. It is used to end conversations that should be starting them.
When someone says a technology is “industry standard,” they usually mean one of three different things that require very different responses.
The first meaning is: this technology is widely adopted across the industry as a whole. This is sometimes true. It always requires asking which part of the industry. A 1,000-person fintech company and a 15-person e-commerce startup are both “in the industry.” Their appropriate standards are not the same.
The second meaning is: this technology is best practice for the problem I’m describing. This requires evidence. Best practice for what scale? What team size? What failure mode? “The CNCF says so” is not evidence when the CNCF is an organisation whose members are primarily vendors and large enterprises with a direct interest in promoting adoption of the technologies they built.
The third meaning is: this technology is what I learned about and I want to use it. This is honest and often fine, as long as it is stated as such rather than dressed up as an objective technical recommendation.
The actual test for any technology choice is simpler: does it solve the problem you have, at the scale you are operating, with the team you have? If yes, it is the right choice. If no, the industry adoption rate is irrelevant.
The Specific Danger of Learning from Scale
There is a particular failure mode in learning engineering primarily from the content produced by companies operating at massive scale. It runs deeper than just technology choices.
When you read Google’s Site Reliability Engineering practices, you are reading engineering culture designed for a company where a single percentage point of reliability difference represents millions of affected users and enormous revenue. The practices make sense at that scale. The cost of implementing them, the tooling, the processes, the organisational structure, is justified by the scale.
When a twelve-person startup implements the same practices, they have taken on the cost without the corresponding benefit. They spend engineering time on runbooks for systems that could be rebuilt from scratch in a day. They build for failure modes they are statistically unlikely to experience. They optimise for the availability requirements of a business with 280 million users when they have 2,800.
The problem is not learning from Google. The problem is learning from Google and forgetting that you are not Google. The architecture posts, the scaling stories, the infrastructure choices all make perfect sense in context. The context is the part that does not transfer.
This produces a specific kind of engineer who can discuss distributed consensus algorithms, explain the CAP theorem fluently and architect a system for five nines of availability. But they have never debugged a slow query in a production database or figured out why a service starts returning 503 errors under moderate load. The theoretical knowledge is real. The operational experience is missing.
What Good Engineering Actually Looks Like in Practice
This is not an argument against complexity. Some systems genuinely require it. Kubernetes exists for good reasons and solves real problems at the scale it was designed for.
The original design brief for Kubernetes was Google’s internal container management system, Borg, which managed tens of thousands of machines running hundreds of thousands of jobs. Google needed a system to orchestrate containers at that scale because that was the actual problem. The tool fits the problem.
The error is not using Kubernetes. The error is using Google’s tools for problems that are not Google’s problems.
Real engineering judgment, the kind that only comes from experience rather than blog posts, involves knowing the difference between a problem that needs Kubernetes and a problem that needs a sticky session. It involves recognising that the sophisticated solution you read about on Friday may be a perfect fit or may be dramatic overkill. Figuring out which requires understanding your actual constraints.
The constraints that matter are specific: How many requests per second? What failure rate is acceptable to the business? How many engineers do you have to maintain this? What happens when the person who built it leaves?
None of those questions are answered by knowing what Netflix does.
The One Thing Tech Twitter Actually Gets Right
To be fair, tech Twitter and engineering blogs do one thing very well. They make it clear that interesting problems exist and that solutions to them have been found. Knowing that distributed systems problems are solvable, that consensus protocols exist, that database sharding is possible: this is genuinely valuable knowledge.
The failure is in the translation from “this exists and is interesting” to “this is what I should build next.” Those are very different propositions.
The best engineers read widely and apply narrowly. They understand the full landscape of what is possible. They then look at the specific problem in front of them and choose the smallest thing that solves it reliably. They are not impressed by their own architecture. They are impressed by systems that work.
The worst engineers read widely and apply liberally. Every interesting technology becomes a solution looking for a problem. Every blog post is an implicit argument for adoption. The resume grows. The system gets harder to understand. The connection leak stays unfixed because it was never interesting enough to write about.
The Lesson That Does Not Come from a Blog Post
Understanding why a tool exists is different from knowing how to use it. The second is learnable in a weekend. The first takes years and requires the specific experience of watching a tool fail in a context it was not designed for.
Kubernetes failing on a three-server deployment is not a Kubernetes problem. It is a mismatch between tool and context. That distinction only becomes intuitive after you have made the mismatch yourself, watched the operational overhead accumulate and realised that simpler would have been better.
This is not something a blog post can fully convey because the blog post about a successful Kubernetes migration was written by someone for whom the migration was successful. It cannot tell you whether the migration would have been successful for you, with your team, your scale and your actual failure modes.
The most important word in “industry standard” is not “standard.” It is “industry.” The industry is not one thing. It is 40-person companies, 400-person companies and 40,000-person companies, all of which have radically different problems, resources and appropriate solutions.
The content that gets the most attention tends to come from the large end of that distribution. The companies at the other end are too busy fixing connection leaks to write about it.
Which, honestly, is exactly what they should be doing.