Most system design tutorials show you the happy path. Production systems have a different opinion.
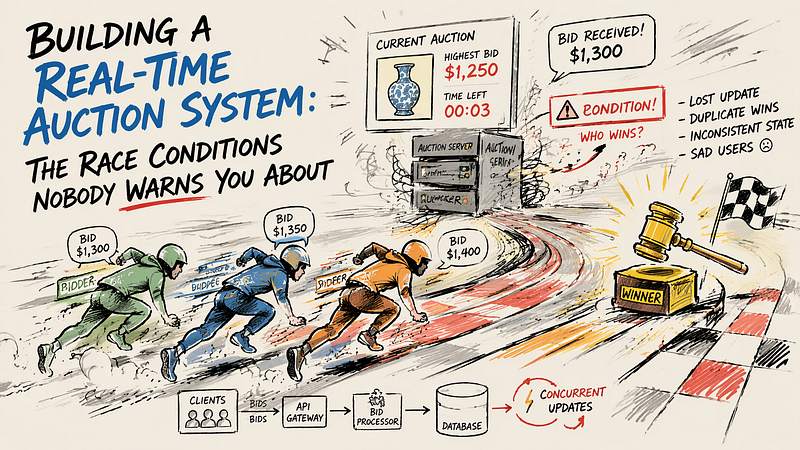
The first time I sat down to design an auction backend, I made the classic mistake: I spent too long thinking about the happy path. User places bid, bid is higher than current price, bid gets accepted. Done. Ship it.
🚀 HIRING High-Paying Tech Job
💰 $50–$120/hr • Multiple Roles Open
Frontend • Backend • Full Stack • AI/ML • DevOps
👉 Apply in Minutes

Three weeks before launch, during load testing, we watched bids vanish. Two users placed the same winning bid at the same millisecond. The database showed both had been accepted. One user got a confirmation. The other got silence. Neither got the item.
That is when the education started.
Building an auction system looks straightforward until you realize it belongs to a category of problem where everything that can go wrong happens simultaneously, at the worst possible time, in front of paying users. Let me walk you through what actually matters and what you can ignore until you genuinely need it.
Why Auctions Break What You Know About CRUD
Most backend systems are forgiving. You insert a record, you update a record, you read a record. If two users submit a form at the same moment, the worst outcome is slightly inconsistent data that a re-sync fixes.
Auctions do not forgive. When two bidders hit submit within milliseconds of each other, your system has to make an authoritative decision: who won? That decision has to be the same whether you are running one database node or twenty application servers.
The core problem is a race condition. Your application reads the current highest bid, evaluates whether the incoming bid qualifies, then writes the new bid. If two requests execute that read-evaluate-write cycle simultaneously, both might read the same “current highest bid,” both conclude they are valid and both get written. You now have two accepted bids at the same price, two winners and one item.
This is not a bug you unit test away. It is a concurrency problem that requires you to think at the database level, not the application level.
What a Race Condition Actually Looks Like
Before looking at the fix, look at the break. Here is the naive bid handler that most backends start with:
// Laravel: the broken version, no locking
function placeBid(int $auctionId, float $incomingBid, int $bidderId): void
{
$auction = Auction::find($auctionId); // 1. READ
if ($incomingBid > $auction->current_bid) { // 2. EVALUATE
$auction->update([ // 3. WRITE
'current_bid' => $incomingBid,
'current_winner_id' => $bidderId,
]);
}
} // Go: the same broken version
func placeBid(ctx context.Context, db *sql.DB, auctionID int64, incomingBid float64, bidderID int64) error {
var currentBid float64
// 1. READ
err := db.QueryRowContext(ctx,
`SELECT current_bid FROM auctions WHERE id = $1`, auctionID,
).Scan(¤tBid)
if err != nil {
return err
}
// 2. EVALUATE + 3. WRITE - nothing is protecting this gap
if incomingBid > currentBid {
_, err = db.ExecContext(ctx,
`UPDATE auctions SET current_bid = $1, current_winner_id = $2 WHERE id = $3`,
incomingBid, bidderID, auctionID,
)
}
return err
}
Now watch what happens when two requests arrive at the same time:
Time Bidder A: $500 Bidder B: $500
──── ────────────────────────────── ──────────────────────────────
T1 READ current_bid = $450
T2 READ current_bid = $450
T3 EVAL $500 > $450 → valid
T4 EVAL $500 > $450 → valid
T5 WRITE current_bid = $500 ✓
T6 WRITE current_bid = $500 ✓
Result: two accepted bids, one item, one very angry customer.Both requests read the same stale value at T1 and T2. Both pass validation. Both write. The database has no idea only one should have succeeded because nothing told it to enforce that constraint. This is not a theoretical edge case. Under any real load, this gap between READ and WRITE is wide enough for a truck to drive through.
The State Machine You Have to Get Right First
Before you write any corrected bid processing logic, define your auction state machine explicitly. Every auction moves through states. A minimal set looks like this:
draft: created but not yet livescheduled: published and awaiting start timeactive: accepting bids right nowending_soon: within the final countdown window, useful for anti-sniping logicclosed: bidding window has ended, awaiting settlementsettled: winner confirmed and item dispatched or reservedcancelled: terminated without a winner
Your bid validation logic must check the auction state before doing anything else. This sounds obvious. You would be surprised how many systems skip this check and get burned when a race condition lets a bid slip in 200 milliseconds after closing time.
Encode these transitions in your application and enforce them at the database level with check constraints. A CHECK constraint on your auctions table that only allows valid state values costs nothing and saves you from garbage data accumulating in production.
The Bidding Race: Where Systems Go to Die
There are two mainstream approaches for preventing duplicate bid acceptance under concurrency: pessimistic locking and optimistic locking. They solve the same problem differently, and the right choice depends on your bid volume.
Pessimistic locking assumes conflicts happen frequently, so it locks the row before doing anything with it. The SQL is the same regardless of your application stack:
-- Acquire an exclusive row lock before reading
SELECT id, current_bid, auction_state
FROM auctions
WHERE id = $1
FOR UPDATEThe FOR UPDATE clause acquires a row-level exclusive lock. Any other transaction attempting to read that row with FOR UPDATE will wait until the first transaction commits or rolls back. Only one transaction evaluates and writes at a time.
Here is what that looks like in application code:
// Laravel: pessimistic lock via Eloquent
DB::transaction(function () use ($auctionId, $incomingBid, $bidderId) {
$auction = Auction::where('id', $auctionId)
->lockForUpdate()
->firstOrFail();
if ($auction->state !== 'active' || $incomingBid <= $auction->current_bid) {
throw new BidRejectedException();
}
$auction->update([
'current_bid' => $incomingBid,
'current_winner_id' => $bidderId,
]);
}); // Go: pessimistic lock via database/sql transaction
func placeBidWithLock(ctx context.Context, db *sql.DB, auctionID int64, incomingBid float64, bidderID int64) error {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return err
}
defer tx.Rollback()
var currentBid float64
var state string
err = tx.QueryRowContext(ctx,
`SELECT current_bid, auction_state FROM auctions WHERE id = $1 FOR UPDATE`,
auctionID,
).Scan(¤tBid, &state)
if err != nil {
return err
}
if state != "active" || incomingBid <= currentBid {
return ErrBidRejected
}
_, err = tx.ExecContext(ctx,
`UPDATE auctions SET current_bid = $1, current_winner_id = $2 WHERE id = $3`,
incomingBid, bidderID, auctionID,
)
if err != nil {
return err
}
return tx.Commit()
}
The lock ensures the READ-EVALUATE-WRITE cycle happens atomically. Bidder B cannot read the row until Bidder A’s transaction finishes. The race condition from the timeline above is gone.
This works. It is safe. The downside is that under high concurrency, you get lock contention. Requests queue up waiting for the lock to release. If your auction is receiving thousands of bids per minute, pessimistic locking on the auction row becomes a bottleneck.
Optimistic locking takes the opposite approach: assume conflicts are rare, so do not lock at all. Read the current state, do your processing, then write only if the row has not changed since you read it. You implement this with a version column:
-- Write only succeeds if version has not changed since we read it
UPDATE auctions
SET current_bid = $new_bid,
current_winner_id = $bidder_id,
version = version + 1
WHERE id = $auction_id
AND version = $expected_version
AND $new_bid > current_bidIf another transaction already incremented the version before yours arrived, your update returns zero affected rows. Your application retries. No lock, no queue, no blocked requests.
The catch: under truly high concurrency, retry storms become your new problem. If fifty processes all read version 7, attempt to write with version 7 and all fail except one, you have just done forty-nine useless database round trips and kicked off forty-nine retries that will all compete again.
For most auctions, pessimistic locking is the right starting point. It is predictable, it is safe and you do not have to reason about retry logic. Switch to optimistic locking when your metrics actually show you need it.
When You Need Redis in the Loop
There is a third approach worth understanding for high-stakes, high-volume scenarios: moving the critical section out of the database and into Redis.
Redis executes commands on a single thread. Operations like INCR, DECR and SET NX are atomic by design. That atomicity is the entire value proposition when you need to prevent race conditions at speed.
Here is the same bid check implemented with a Redis atomic lock, in both stacks:
// Laravel: Redis atomic lock via Cache::lock()
$lock = Cache::lock('auction:lock:' . $auctionId, 5);
if ($lock->get()) {
try {
$currentBid = Cache::get('auction:bid:' . $auctionId, 0);
if ($incomingBid > $currentBid) {
Cache::put('auction:bid:' . $auctionId, $incomingBid, 300);
// Defer the database write to a queue worker
ProcessBidUpdate::dispatch($auctionId, $incomingBid, $bidderId);
}
} finally {
$lock->release();
}
} // Go: Redis atomic lock via go-redis SetNX
import (
"github.com/redis/go-redis/v9"
"github.com/google/uuid"
"time"
"fmt"
)
func placeBidWithRedis(ctx context.Context, rdb *redis.Client, auctionID int64, incomingBid float64, bidderID int64) error {
lockKey := fmt.Sprintf("auction:lock:%d", auctionID)
bidKey := fmt.Sprintf("auction:bid:%d", auctionID)
token := uuid.New().String()
// SET lockKey token NX EX 5 - atomic, only one process wins
acquired, err := rdb.SetNX(ctx, lockKey, token, 5*time.Second).Result()
if err != nil || !acquired {
return ErrLockNotAcquired
}
defer rdb.Del(ctx, lockKey)
currentBid, err := rdb.Get(ctx, bidKey).Float64()
if err != nil && err != redis.Nil {
return err
}
if incomingBid > currentBid {
if err := rdb.Set(ctx, bidKey, incomingBid, 5*time.Minute).Err(); err != nil {
return err
}
// Enqueue database persistence - do not block the hot path
return enqueueBidUpdate(ctx, auctionID, incomingBid, bidderID)
}
return nil
}
Laravel’s Cache::lock() uses Redis's SET NX EX under the hood when Redis is your cache driver. The Go version does the same thing explicitly with SetNX. Both create the lock key only if it does not exist, with an automatic expiry so a crashed process cannot cause a deadlock. The finally block in PHP and defer in Go guarantee release even when an exception or early return fires mid-execution.
What this buys you: the hot path for bid evaluation happens in Redis, which is orders of magnitude faster than acquiring a database row lock. The database write is deferred to a queue worker. Your API endpoint responds fast, your users see the result quickly and your database is protected from a thundering herd of concurrent writes.
What it costs you: you now have two sources of truth during the window between the Redis update and the database commit. If your Redis instance goes down before the queue flushes, bids can be lost. This is an acceptable trade-off for non-financial goods. For anything with payment implications, you need a more careful architecture where the queue worker writes with idempotency guarantees.
Real-Time Updates Without Overengineering
Every bidder in an active auction needs to see the current price update when someone else bids. The instinct is to reach for WebSockets immediately. Sometimes that is right. Sometimes it is not.
WebSockets establish a persistent, bidirectional connection between client and server. They are the correct tool when clients need to both send and receive data in real time. For auctions, that bidirectionality is genuinely useful: a bidder might want to place a bid and receive updates through the same connection.
Server-Sent Events are the alternative: a persistent HTTP connection where only the server sends data. Simpler to implement, they reconnect automatically on network hiccups and work through standard HTTP infrastructure, so your load balancer requires no special configuration.
For most auction UIs, the architecture that actually works is: bids are placed via a regular HTTP POST endpoint, and real-time updates are pushed to clients through a channel that all connected clients subscribe to. Separating bid submission from bid display simplifies your stack considerably.
At the infrastructure level, this means your real-time server needs a pub/sub mechanism to broadcast bid updates to all connected clients without each client polling your database. Redis Pub/Sub handles this cleanly: when a bid is accepted, publish a message to the auction channel and your WebSocket or SSE server relays it to all subscribers watching that auction. Your database never gets hammered by polling.
The Settlement Problem Nobody Talks About
Getting bids accepted correctly is problem one. Settling the auction correctly is problem two, and it bites teams harder because it happens during a quieter window that gets less testing time.
When an auction closes, you need to lock the auction against further bids, identify the winning bid, notify the winner, initiate payment or reservation and notify all other bidders. Each step is a potential failure point.
Clock drift between servers means auctions can close at slightly different times on different nodes. Your notification service can fail. Your payment gateway can return an ambiguous response that leaves you unsure whether the charge went through.
Design your settlement flow as a durable job, not a synchronous API call. The moment bidding closes, enqueue a settlement job with idempotency guarantees. If it fails mid-execution, it must be safe to retry from the beginning without double-charging or double-notifying anyone.
The specific pattern: write your settlement attempt to the database before calling any external service. If the job crashes after the database write but before the payment call, your retry logic detects the existing record and resumes correctly.
INSERT INTO settlement_attempts (auction_id, attempt_id, status, created_at)
VALUES ($auction_id, $idempotency_key, 'pending', NOW())
ON CONFLICT (auction_id, attempt_id) DO NOTHINGThat ON CONFLICT DO NOTHING is doing real work. It makes your settlement job safe to retry without creating duplicate records, no matter how many times the job fires.
Building for the Real Scale, Not the Dream Scale
Here is the thing most system design articles will not tell you: most auctions do not need Kafka, Kubernetes or Redlock spread across five Redis nodes. They need a sensible schema, row-level locks applied consistently and a queue worker that does not fall over.
The architecture above, with PostgreSQL FOR UPDATE for concurrency control and Redis Pub/Sub for real-time broadcast, handles hundreds of simultaneous bidders without exotic infrastructure. The problems most teams hit are not scale problems. They are design problems that show up at modest load because the fundamentals got skipped in the rush to implement the interesting parts.
The checklist before you deploy:
State transitions enforced in the database, not just in application code. Bid acceptance behind a lock, pessimistic or optimistic depending on your actual expected volume. Settlement as an idempotent job, not an inline call that fails silently. Real-time updates going through a pub/sub channel so your web servers are not doing fan-out to hundreds of connected sockets manually.
Get those four things right and you can worry about higher-throughput infrastructure when you are actually processing tens of thousands of bids per second. Until then, your biggest risk is not throughput. It is correctness.
The Code You Ship Is Not Your Architecture Document
One last thing worth saying: the race conditions that will actually hit you in production are not the ones in your diagrams. They are the ones you did not consider because the happy path looked so obvious.
The bid that arrives three seconds after close because the client's clock was wrong. The settlement job was fired twice because the first invocation timed out before writing its heartbeat. The Redis lock that was never released because someone threw an uncaught exception before the finally block.
These are not architectural failures. They are edge cases that only surface because your architecture is working most of the time. Build your happy path correctly, then go looking for the failure modes. The auction system that does not embarrass you in production is the one where you found those edge cases in staging rather than at 2 am during a live sale.
Thank you for being a part of the community
Before you go:

👉 Be sure to clap and follow the writer ️👏️️
👉 CodeToDeploy Tech Community is live on Discord — Join now!
Disclosure: This post includes affiliate and partnership links.


